 macklus
macklusSince a while ago I started moving all the services that I currently have towards serverless systems, I also started looking for...
Analyze use of S3 with CloudTrail and Athena
 macklus
macklus También puedes leer este apunte en castellano pulsando aquí.
A few days ago, when analyzing the consumption of S3 from one of our header projects, we saw that the cost was skyrocketing. In this project we use S3 as a static image store, which is accessed from a CloudFront distribution, so it should not be very high.
One of the problems of using this type of configuration is that, given a problem like this, processing and debugging possible concept or operation failures is very complicated, since both CloudFront and S3 are services managed by AWS, and we do not have a Direct access to debug information. To be able to do this analysis we must use the services of AWS CloudTrail, S3 and Athena.
The analysis process
The process to be followed to carry out the analysis is shown in the following image
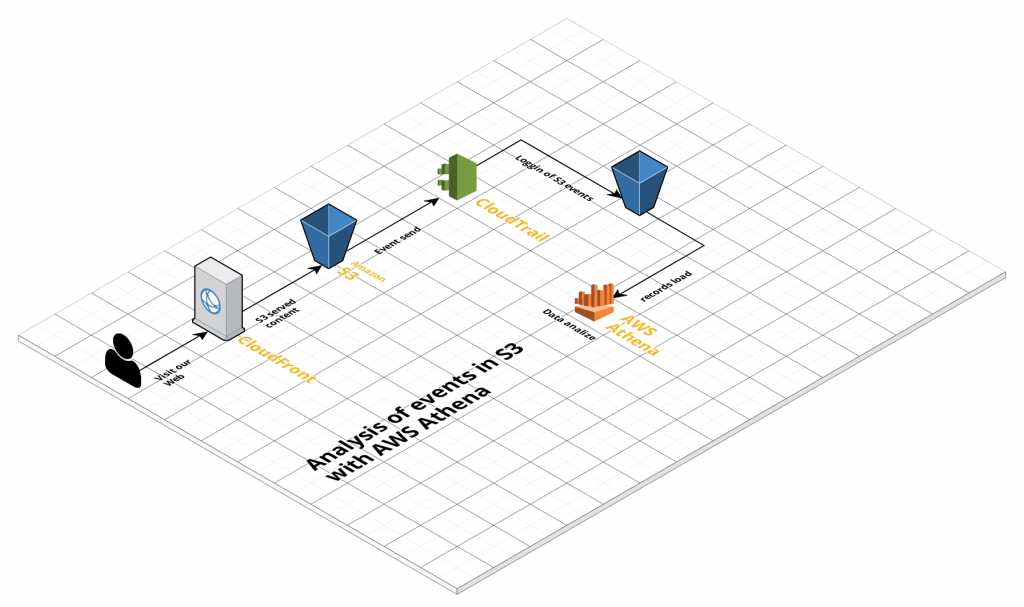
The steps to configure it will be:
- Configure CloudTrail to save S3 events in an S3 bucket
- Configure Athena to read S3 data
- Analyze records with Athena
Configure CloudTrail to save S3 events
AWS CloudTrail is a service for auditing in Amazón web services. For each of the audits we want to perform, we must create a “trail” that will save the information in S3, either for storage or for further analysis.
To create a new trail, we will go to the CloudTrail console, and:
- Click on the “Create Trail” button
- We indicate the name in the “Trail name” box
- Select “no” in the “Apply trail to all regions” box
- Select “None” in the “Read / Write events” box
- In the “Data events” tab we must indicate the S3 bucket or buckets that we want to audit
- In the “Storage location” tab we must indicate the S3 bucket where we want to save the records (it is recommended to create a new bucket)
Now, we have to wait a while until the records start appearing in our S3 bucket.
Configure Athena to read S3 data
In order for AWS Athena to be able to interpret the log data that we have saved in S3, it is necessary to create an Athena table, and indicate the structure of the log files. Thus, Athena can separate and analyze the data of each registry entry, and will allow us to make complex queries about that content.
To create the new table and define the records, we can use Athena’s own language, launching the following query from the editor:
CREATE EXTERNAL TABLE cloudtrail_logs (
eventversion STRING,
useridentity STRUCT<
type:STRING,
principalid:STRING,
arn:STRING,
accountid:STRING,
invokedby:STRING,
accesskeyid:STRING,
userName:STRING,
sessioncontext:STRUCT<
attributes:STRUCT<
mfaauthenticated:STRING,
creationdate:STRING>,
sessionissuer:STRUCT<
type:STRING,
principalId:STRING,
arn:STRING,
accountId:STRING,
userName:STRING>>>,
eventtime STRING,
eventsource STRING,
eventname STRING,
awsregion STRING,
sourceipaddress STRING,
useragent STRING,
errorcode STRING,
errormessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestid STRING,
eventid STRING,
resources ARRAY<STRUCT<
ARN:STRING,
accountId:STRING,
type:STRING>>,
eventtype STRING,
apiversion STRING,
readonly STRING,
recipientaccountid STRING,
serviceeventdetails STRING,
sharedeventid STRING,
vpcendpointid STRING
)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://s3-inspect-bucket/AWSLogs/';With this query we will create the cloudtrail_logs table, which we will then use to make the different requests. It is important to keep in mind that the LOCATION field must point to the S3 bucket where we are keeping the records.
It is important to keep in mind that Athena will charge us for each request, depending on the volume of data we analyze, so it is advisable to use a small data group to debug the queries, before executing them against the total data group, to avoid That the cost can grow up.
Analyze records with Athena
To analyze the records with Athena, we will create queries in SQL language very similar to the standard.
In my case, we wanted to debug the use that was being made of S3, these are the queries I used:
See the number of requests to each S3 bucket
SELECT
COUNT(*) as total,
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName'] AS bucketName
FROM cloudtrail_logs
GROUP BY
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName']
ORDER BY total DESC;In this case, since the name of the bucket is within the requestparameters field, we must remove it from the JSON object that forms it.
Group requests by UserAgent
SELECT
COUNT(useragent) as total,
useragent
FROM cloudtrail_logs
WHERE CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName'] = 'testbucket-data'
GROUP BY
useragent,
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['bucketName']
ORDER BY total DESC;Once we knew the bucket where most of the requests were made, with this query we took out the UserAgent of the clients that are making the requests.
In this case we have used the UserAgent of the request to see who was making the requests, since the AWS internal processes also send us a UserAgent and allow us to discriminate the origin.
Show the most requested S3 keys
SELECT
COUNT(CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['key']) as total,
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['key'] AS key
FROM cloudtrail_logs
GROUP BY
CAST(json_parse(requestparameters) AS MAP(VARCHAR, VARCHAR))['key']
ORDER BY total DESC
LIMIT 100With this request we show the 100 S3 keys that have received the most requests, also showing the total number of requests. This query helped us to see that there were several keys that were receiving an abnormally high number of requests, and debug what the problem was.
